Large Language Model Development Accelerated by NVIDIA and Anyscale Collaboration
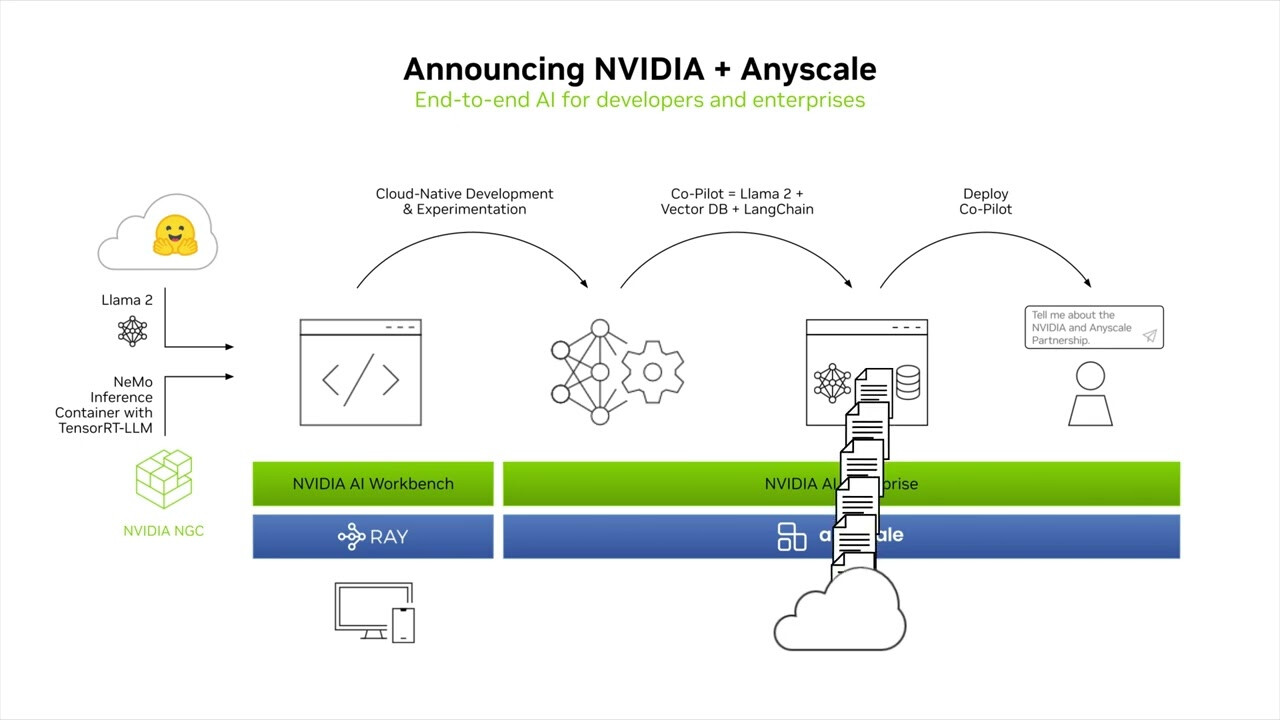
At the annual Ray Summit developers conference, Anyscale announced a collaboration with NVIDIA to bring NVIDIA AI to Ray open source and the Anyscale Platform. This collaboration aims to speed up generative AI development and efficiency while enhancing security for production AI. The integration of NVIDIA AI into Anyscale Endpoints will make it easier for application developers to embed LLMs in their applications using popular open source models.
The collaboration between NVIDIA and Anyscale will support various LLM models, including Code Llama, Falcon, Llama 2, SDXL, and more. Developers will have the option to deploy open-source NVIDIA software with Ray or choose NVIDIA AI Enterprise software on the Anyscale Platform for a fully supported and secure production deployment. Ray and the Anyscale Platform are widely used by developers to build advanced LLMs for generative AI applications such as chatbots, coding copilots, and search tools.
NVIDIA TensorRT-LLM, a new open-source software, will support Anyscale offerings to enhance LLM performance and efficiency, resulting in cost savings. TensorRT-LLM scales inference to run models in parallel over multiple GPUs, providing up to 8x higher performance on NVIDIA H100 Tensor Core GPUs compared to previous-generation GPUs. It also includes custom GPU kernels and optimizations for popular LLM models and offers an easy-to-use Python interface.
NVIDIA Triton Inference Server software enables inference across various devices and processors, including GPUs, CPUs, and embedded devices. Its integration with Ray allows developers to improve efficiency when deploying AI models from multiple deep learning and machine learning frameworks.
The NVIDIA NeMo framework allows Ray users to fine-tune and customize LLMs with business data, enabling LLMs to understand the unique offerings of individual businesses. NeMo is a cloud-native framework that offers training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models.
Developers can choose between Ray open source and the Anyscale Platform to deploy production AI at scale in the cloud. The Anyscale Platform provides fully managed, enterprise-ready unified computing, making it easy to build, deploy, and manage scalable AI and Python applications using Ray. The collaboration between NVIDIA and Anyscale will enable developers to build, train, tune, and scale AI more efficiently.
Ray and the Anyscale Platform run on accelerated computing from leading clouds, allowing developers to easily scale up as needed. The collaboration will also enable developers to build models on their workstations using NVIDIA AI Workbench and scale them across hybrid or multi-cloud accelerated computing for production.
The NVIDIA AI integrations with Anyscale are currently in development and expected to be available by the end of the year. Developers can sign up to receive the latest news on this integration and a free 90-day evaluation of NVIDIA AI Enterprise.
To learn more, attend the Ray Summit in San Francisco or watch the demo video below: